Redes Neurais Artificiais são métodos de calibração bem estabelecidos com vantagens explícitas na modelagem de bancos de dados grandes e complexos. O princípio básico da ANN será apresentado e o ‘poder’ das ANN exemplificado por um estudo de caso sobre a previsão de Cor em amostras de Açúcar utilizando o NIRS DS2500 da FOSS.
Douglas Beletti e Vinícius Passos, CETEC Equipamentos, 2021.
Do cérebro para o computador
A inspiração original para o desenvolvimento de redes neurais artificiais veio da neurociência. Os neurônios do cérebro estão conectados por meio de redes complexas e esse conceito foi a inspiração para a Rede Neural Artificial como uma analogia à rede neural biológica humana. O cérebro humano possui habilidades extraordinárias de reconhecimento de padrões com respeito ao mundo ao nosso redor; com base na entrada para os sentidos transmitidos ao cérebro, as decisões são tomadas e os padrões são discernidos e reconhecidos com grande confiança. Por outro lado, é muito difícil para o cérebro humano extrair informações qualitativas e, especialmente, quantitativas sobre parâmetros em amostras utilizando os espectros NIR – nesses casos, as Redes Neurais Artificiais farão um excelente trabalho.
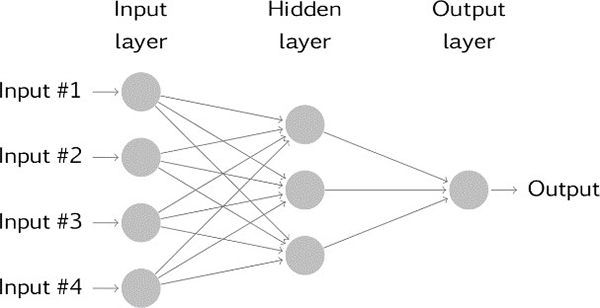
Network design
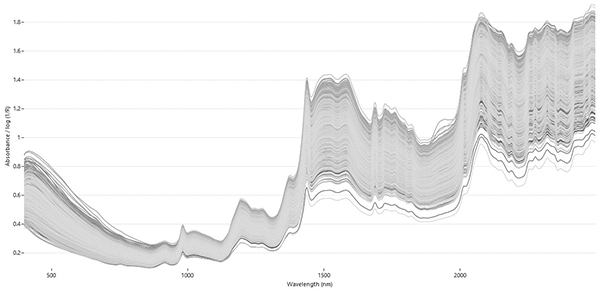
Uma rede neural pode ter vários designs; como exemplo, vamos nos concentrar nas chamadas redes de duas camadas pro-alimentadas que incluem a) entradas, b) uma camada oculta e c) uma camada de saída – consulte a Figura 2 (as entradas não contam como camadas na terminologia ANN). Os neurônios de entrada – primeira camada de neurônios ou unidades – representam simplesmente os valores espectrais registrados; no caso de espectros de transmissão NIR de açúcar, temos registros para cada 0,5 nm de 400 nm a 2500 nm correspondendo a 4200 dados de entrada. Diferentes métodos de pré-processamento podem ser aplicados antes de alimentar os espectros na rede; não os descreveremos aqui, mas enfatizaremos que o pré-processamento inteligente é essencial para obter modelos robustos e de bom desempenho; na FOSS, usamos um estágio de pré-processamento matemático proprietário antes que as calibrações de rede neural artificial sejam desenvolvidas.
Determinação de cor no açúcar utilizando redes neurais artificiais
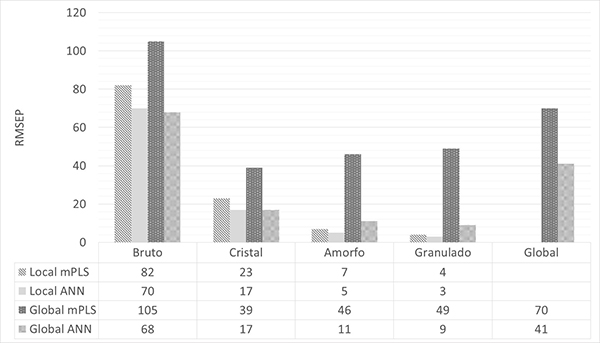
Ao utilizar modelos de previsão baseados em redes neurais artificiais abrimos a possibilidade de lidar com problemas não lineares e também utilizar o sistema de agrupamentos de padrões para prever com maior acurácia em uma calibração local, global ou também com diferentes produtos – o que chamamos aqui de multi-product calibration. Aqui avaliaremos a previsão do parâmetro COR em amostras de diferentes tipos de açúcar, contemplando VHP, Cristal, Amorfo e Granulado e comparamos a capacidade dos modelos ANN modelar não linearidades em relação ao mPLS e suas performances a partir dos valores RMSEP (Erro Padrão de Previsão) em comparação com os modelos locais, também nos dois algoritmos.
Banco de dados
É extremamente importante ter o máximo de variação relevante representada em seu banco de dados de calibração para obter previsões robustas e precisas, bem como para garantir a estabilidade ao longo do tempo.
O banco de dados FOSS/CETEC utilizado para confecção do modelo apresenta as seguintes características:
- Mais de 25.000 amostras de açúcar;
- Amostras coletadas em diferentes regiões ao longo de 5 safras com diferentes processos, geografias e sazonalidades;
- Diferentes tipos de açúcar entre eles VHP, VVHP, Cristal, Refinado Amorfo e Refinado Granulado;
- Faixa de 10 a 2000 UI;
- Diferentes instrumentos NIRS DS2500.
Desenvolvimento do modelo & previsão
O modelo ANN foi treinado com as 25.000 amostras do banco de dados para obter a configuração ideal de todos os pesos na rede – como descrito, esta é uma tarefa complexa, mas pode ser facilmente realizada pelo computador. Quando ANN é treinada, os pesos são fixos e temos um modelo onde conhecemos todas as configurações e agora é fácil realizar a previsão da cor para uma nova amostra. O espectro é registrado (50 segundos) e inserido na arquitetura da ANN com os pesos treinados. Por pré-processamento, multiplicação, adição e transferência de função não linear desses dados de entrada, obtemos uma estimativa do conteúdo de cor da amostra analisada. Na Figura 3, o modelo é avaliado no conjunto de teste independente cobrindo todas as variações possíveis e também comparado com os diferentes tipos açúcares e seus modelos locais. O valor RMSEP (Erro Padrão de Previsão) varia de acordo com o tipo de açúcar e faixa de cor conforme método ICUMSA e tanto localmente quanto globalmente os modelos ANN apresentam melhor performance.
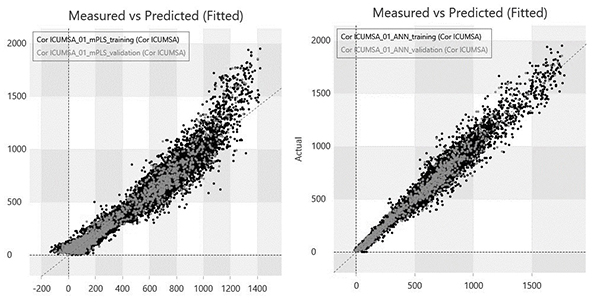
Os modelos lineares não são capazes de lidar com esses dados não lineares e terão um desempenho muito inferior que o modelo ANN como podemos visualizar nas regressões da figura 4.
Conclusão
As redes neurais artificiais são muito eficientes para a extração de informações quantitativas de grandes bancos de dados espectroscópicos onde a não linearidade é inerente devido a complexas variações biológicas, ambientais e instrumentais. A base para um modelo de ANN de bom desempenho é um banco de dados abrangente que contemple todas as variações relevantes e ferramentas de modelagem eficientes e otimizadas. A combinação de ANN e um banco de dados bem estruturado oferece maior robustez, estabilidade e por último, mas não menos importante, precisão. Os modelos globais ANN possuem várias vantagens sobre os modelos locais mPLS em relação ao monitoramento do processo: [1] a implementação dos modelos globais ANN permitem uma simples manutenção de calibrações porque apenas um modelo por parâmetro de qualidade teria que ser mantido. [2] a implementação permite uma estimativa mais precisa dos parâmetros de qualidade e, portanto, um melhor monitoramento do processo.
A empresa Cetec é patrocinadora do Webmeeting Fermentec 2021/22 Reunião Início de Safra